The worst kind of data provision is flat file text CSV! It’s just a massive pain… and usually out of control from a data governance point of view.
This some example code and suggestions how to handle CSV’s ingest. The best way I find from a data engineering perspective is to just load the whole line in 1 field as a string. Store that convert it, shred it and validate it… this gives the best of all worlds:
- We can load it fast using a controlled schema so no double hit on inferring the schema on read, it’s just 1 string column -> the csv string
- Any new fields just auto feed into raw
- No typing out and maintaining hundreds of cast statements – we just have to declare the spark schema; and a little secret I don’t type that out either, there’s a little trick to get it tweak it I’ll show in another blog
- We can easily detect alert any new fields as soon as provided – no back filling
- We can validate the CSV using a JSON schema applying more advanced data quality jail in the raw layer – will include this in separate blog
- When and if we’re ready to use the new fields it’s there to take from the raw layer with no messing around with data providers and dependencies outside our world making changes to add the field
So here is a simplified example done in databricks….
Here is the Function !
%scala
import org.apache.spark.sql.{DataFrame}
import org.apache.spark.sql.types.{DataType, StructType}
import org.apache.spark.sql.functions._
def formatCsv(df:DataFrame, schema:StructType, column:String, asJson:Boolean=false, separator:String=",") =
{
//split the csv string into an Array column inside the data frame
var _df = df.withColumn(column, split(col(column),separator))
//for each field in the schema
//create a new column and give it the column name and data type
var i = 0 // we have to create a self incrementing indexer here so that we can access the array ordinal into the dataframe
// this obviously assumes the schema columns and the array MUST be in the same order.
schema.map(
field => {
//create the new columns
_df = _df.withColumn(field.name, col(column)(i))
_df = _df.withColumn(field.name, expr(s"cast(${field.name} as ${field.dataType.simpleString})"))
//increment the indexer
i += 1
}
)
//drop the array columns since we're done with it
_df = _df.drop(col(column))
//convert the dataframes rows to a dataframe of json text lines.
if (!asJson) _df else _df.toJSON.select($"Value".as(column))
}
Generate some example data
%scala
//declare the schema
val schemaJson = """
{"type":"struct","fields":[
{"name":"ThisIsAnInt" ,"type":"integer","nullable":true,"metadata":{}},
{"name":"ThisIsADouble" ,"type":"double","nullable":true,"metadata":{}},
{"name":"ThisIsAString" ,"type":"string","nullable":true,"metadata":{}},
{"name":"ThisIsABoolean" ,"type":"boolean","nullable":true,"metadata":{}},
{"name":"ThisIsATimestamp","type":"timestamp","nullable":true,"metadata":{}}]}
"""
val schema = DataType.fromJson(schemaJson).asInstanceOf[StructType]
//generate an example data set
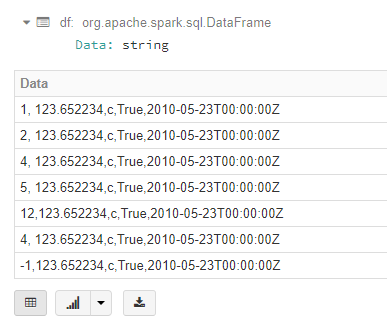
var df = Seq(
("1, 123.652234,c,True,2010-05-23T00:00:00Z"),
("2, 123.652234,c,True,2010-05-23T00:00:00Z"),
("4, 123.652234,c,True,2010-05-23T00:00:00Z"),
("5, 123.652234,c,True,2010-05-23T00:00:00Z"),
("12,123.652234,c,True,2010-05-23T00:00:00Z"),
("4, 123.652234,c,True,2010-05-23T00:00:00Z"),
("-1,123.652234,c,True,2010-05-23T00:00:00Z")
).toDF("Data")
//have a look at it
display(df)
Convert to data frame
%scala //convert the csv string row to a typed flat data frame val tbl = formatCsv(df, schema, column="Data", asJson=false) display(tbl)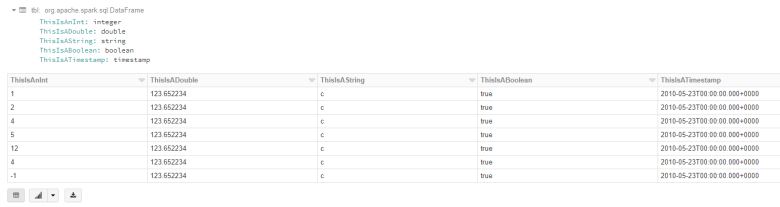
Convert to json string data frame
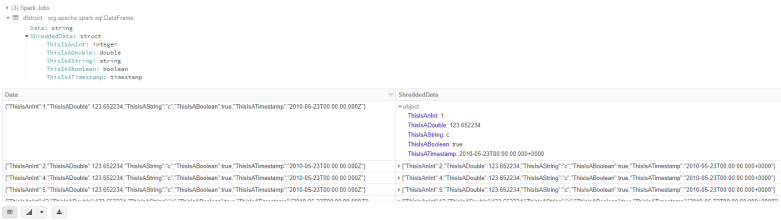
%scala //convert the csv string row in to a json string row val json = formatCsv(df, schema, column="Data", asJson=true) display(json)
Shred json string to Struct
%scala
//convert the csv string row in to a struct
val dfstruct = formatCsv(df, schema, column="Data", asJson=true).withColumn("ShreddedData", from_json($"Data", schema))
display(dfstruct)